สอนทำ Web Scraping ด้วย Python เพื่อดึงข้อมูลจากเว็บไซต์
ต้องการดึงข้อมูลจากหน้าเว็บไซต์ต่าง ๆ แบบอัตโนมัติโดยที่ไม่ต้อง copy/paste แบบ manual ซึ่งกว่าจะทำเสร็จก็ใช้เวลานานมาก ? เพื่อลดงานในส่วนนี้ หรือไม่ว่าจะเป็นเว็บนั้น ๆ ไม่มี API มาให้ใช้เพื่อให้เราดึงข้อมูล ดังนั้นจึงมีวิธีการหนึ่งในทางโปรแกรมมิ่งที่เราสามารถทำได้ เราจะเรียกเทคนิคนี้ว่า "การทำ Web Scraping"
Web Scraping คืออะไร?
Web Scraping คือ วิธีการในการดึงหรือสกัดเอาข้อมูลจากเว็บไซต์ต่าง ๆ ด้วยการใช้ซอฟต์แวร์ในการ scrape ข้อมูล หรือไม่ว่าจะเป็นการเขียนโปรแกรมด้วยภาษา Scripting Language อย่างภาษา Python เพื่อดึงข้อมูลเหล่านั้นมา โดยหน้าเว็บที่เราจะทำ web scraping ต้องเป็น public data อนุญาตให้เราสามารถดึงข้อมูลได้
Web Scraping ผิดกฎหมาย?
เราต้องดูให้ดีว่าหน้าเว็บไหนที่เราสามารถทำ Web Scraping ได้ เพื่อที่จะได้ไม่ขัดต่อกฏหมายและละเมิดข้อมูลส่วนบุคคล คือต้องอ่านรายละเอียดและสังเกตดูให้ดีครับว่าเว็บไหนทำได้หรือไม่ได้ ตัวอย่างดังต่อไปนี้
- เว็บไซต์ที่มีข้อกำหนดในการให้บริการ (Terms and Services) ที่ห้ามดึงข้อมูลจากเว็บอย่างชัดเจน (คือห้ามมา scrape หน้าเว็บฉันนะ เออถ้าแบบนี้คือชัดเจนเลยแฮะ)
- เว็บไซต์ที่ใช้ CAPTCHA (ชัดเจนครับว่าเว็บนี้ต้องป้องกัน bot หรือระบบ automation)
- เว็บไซต์ที่เราต้องทำการยืนยันตัวตน (Authentication System) พูดง่าย ๆ ก็คือเว็บที่เราต้องทำการล็อกอินเพื่อเข้าใช้งาน
ด้านบนก็คือข้อสังเกตของการทำ web scraping ที่อาจจะขัดหรือละเมิดต่อกฎหมายได้ครับ ยังไงก็ลองสังเกตและศึกษาเว็บไซต์เป้าหมายของเราให้ดีก่อนนะครับ
เริ่มต้นทำ Web Scraping ด้วย Python
ต่อมาเราก็จะมาเริ่มทำ Web Scraping กันแล้วครับด้วยภาษาที่นิยมที่สุดคือ Python โดยสเต็ปแรกต้องติดตั้งไลบรารีที่จำเป็นอยู่ 2 ตัว
- Requests
- BeautifulSoup4
Note: เพื่อน ๆ สามารถเลือกเครื่องมือเขียนโค้ดได้ตามใจชอบ เช่น VS Code, Sublime Text, Jupyter Notebook, ฯลฯ แต่ในบทความนี้ผมใช้ VS Code ครับ โดยสร้างไฟล์ที่ต้องการแล้วรันด้วย python ได้เลย เช่น web_scraping.py ก็รันใน terminal เป็น python web_scraping.py เป็นต้น
รู้จัก BeautifulSoup4 และ Requests
BeautifulSoup4 คือ ไลบรารี่ที่เราจะใช้จัดการกับ HTML Elements และ Attributes ต่าง ๆ ที่เราได้ไป scrape มาในแต่ละหน้าเว็บ ซึ่งจะจัดการส่วนต่าง ๆ ให้เราทั้งหมด
Requests คือ ไลบรารี่สำหรับเรียกใช้งาน HTTP Methods ต่าง ๆ ไม่ว่าจะเป็น GET, POST, PUT, DELETE เป็นต้น ซึ่งเป็นหลักการพื้นฐานของเว็บที่เราควรรู้
ติดตั้ง BeautifulSoup
ทำการติดตั้ง BeautifulSoup4 ด้วยคำสั่ง
pip install beautifulsoup4ติดตั้ง requests
ทำการติดตั้ง requests ด้วยคำสั่ง
pip install requestsเช็คว่าไลบรารี่ติดตั้งสำเร็จเรียบร้อยดีหรือไม่
pip freeze ไลบรารี่ทั้ง beautifulsoup4 และ requests ถูกติดตั้งเรียบร้อยดีไม่มีปัญหา (แต่ก็จะมี libs ตัวอื่นปนมาด้วยบางส่วน ไม่ใช่ปัญหาครับ)
beautifulsoup4==4.12.2
certifi==2023.11.17
charset-normalizer==3.3.2
idna==3.6
requests==2.31.0
soupsieve==2.5
urllib3==2.1.01. อิมพอร์ตไลบรารี่ที่เกี่ยวข้อง
import requests
from bs4 import BeautifulSoup2. กำหนด URL ของเว็บที่เราจะสกัด (Scrape) เอาข้อมูล ซึ่งในบทความนี้เราจะมาสกัดเอาชื่อบทความของเว็บ Free Code Camp สุดยอดเว็บในดวงใจของเหล่าโปรแกรมเมอร์อีกเว็บนั่นเองครับ
url = "https://freecodecamp.org/news/"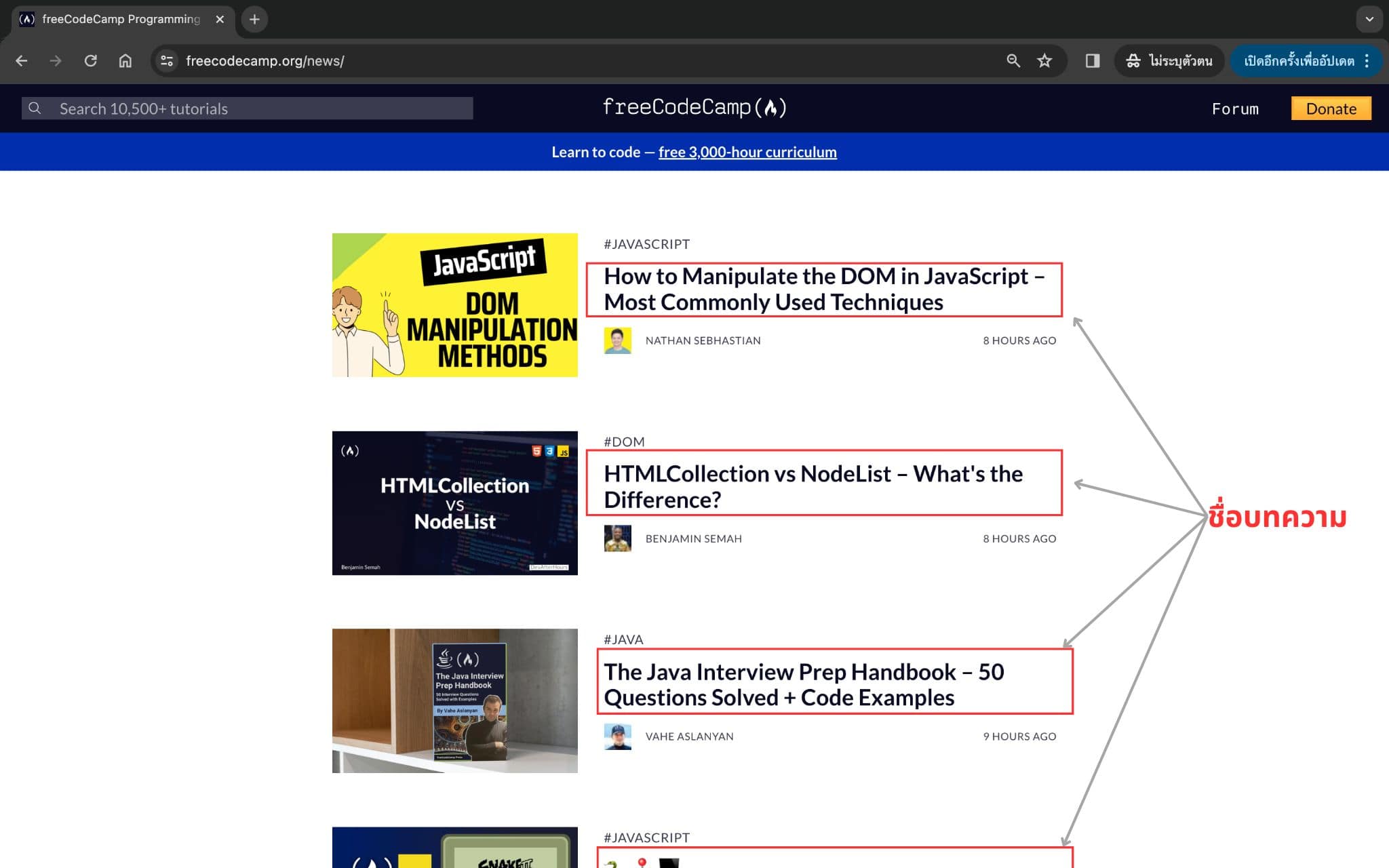 หน้าเว็บที่เราจะ scrape ข้อมูลในบทความนี้
หน้าเว็บที่เราจะ scrape ข้อมูลในบทความนี้
3. ส่ง GET request เพื่อดึงข้อมูลจากตัวแปร url ที่กำหนดไว้ก่อนหน้า
response = requests.get(url)4. เมื่อได้ elements ทั้งหมดของหน้าเว็บเพจมาแล้ว ทำการกำหนดตัวแปร soup เพื่อเรียกใช้งานความสามารถของพระเอกของเราในวันนี้ นั่นก็คือคลาส BeautifulSoup() เพื่อสกัดเอาข้อมูลทั้งหมดออกมา เพื่อที่เราจะสามารถเข้าถึงข้อมูลใน HTML Tags แบบง่าย ๆ ได้ในขั้นตอนต่อไป
soup = BeautifulSoup(response.content, "html.parser")5. ทดสอบแสดงผลข้อมูลที่เราต้องการจะสกัดออกมาด้วยคำสั่ง print()
print(soup)จะเห็นว่ามี HTML code เต็มไปหมดใช่ไหมครับ ซึ่งยังไม่ใช่สิ่งที่เราต้องการ แต่เบื้องต้นนั้นก็ถือว่า scrape ข้อมูลได้แล้ว
6. ทำการเลือก scrape ข้อมูลที่ต้องการ ในที่นี้ก็คือชื่อบทความ โดยชื่อบทความของ Free Code Camp หรือเว็บส่วนใหญ่ทั่วไปแล้วก็จะใช้แท็ก <h2>
titles = []
for title in soup.find_all("h2"):
titles.append(title.get_text().strip())โดย flow ของโค้ดด้านบน
- สร้างตัวแปร empty list ชื่อ titles
- ลูปข้อมูล พร้อมค้นหาแท็ก h2 ด้วยเมธอด find_all()
- เพิ่มข้อมูลเข้าไปใน empty list
หรือจะเขียนเป็นแบบ List Comprehension (ผลลัพธ์เดียวกันกับด้านบนแต่โค้ดสั้นกว่า ในบรรทัดเดียว)
titles = [title.get_text().strip() for title in soup.find_all("h2")]ลอง print ดูว่าได้อะไรมา ซึ่งข้อมูลที่ได้ก็คือได้ชื่อบทความต่าง ๆ เรียบร้อย เก็บอยู่ในประเภทข้อมูลแบบ list
['How to Manipulate the DOM in JavaScript – Most Commonly Used Techniques', "HTMLCollection vs NodeList – What's the Difference?", 'The Java Interview Prep Handbook – 50 Questions Solved + Code Examples', '🐍 🕹️ 💻', 'How to Use setTimeout in React Using Hooks', 'What is the Static Initialization Order Fiasco in C++? [Solved]', 'The Software Engineer Internship Handbook – How to Launch Your Coding Career', 'How to Use the SWR Library for Better Data Fetching in React', 'Python Use Cases – What is Python Best For?', 'How to Set Up GitHub OAuth in a Django App for User Authentication', 'How to Contribute to Open Source as a Community Manager', 'AWS Certified Cloud Practitioner Study Course – Pass the Exam With This Free 14-Hour Course', 'Keeping Time in C++: How to use the std::chrono API', 'How to Use React Hooks – useEffect, useState, and useContext Code Examples', 'MLOps Course – Learn to Build Machine Learning Production Grade Projects', 'SVG Tutorial – How to Code Images with 12 Examples', 'How to Add a Table of Contents to Your Article on Ghost', 'How to Use JavaScript Arrow Functions – Explained in Detail', 'How to Create HTML Accordion Elements With and Without JavaScript', 'How to Build a Clang AST-Based C++ Static Analysis\xa0Tool', 'Code and Deploy an Instagram Clone with React and Firebase', 'API Documentation Best Practices Course', 'How to Use Logic in JavaScript – Operators, Conditions, Truthy/Falsy, and More', 'Advanced Music Production with FL Studio – Tutorial', 'Why You Might Want to Move Your Workloads Out of the Cloud']7. Loop ข้อมูลออกมาแสดงผล
for title in titles:
print("-", title)จะได้ผลลัพธ์
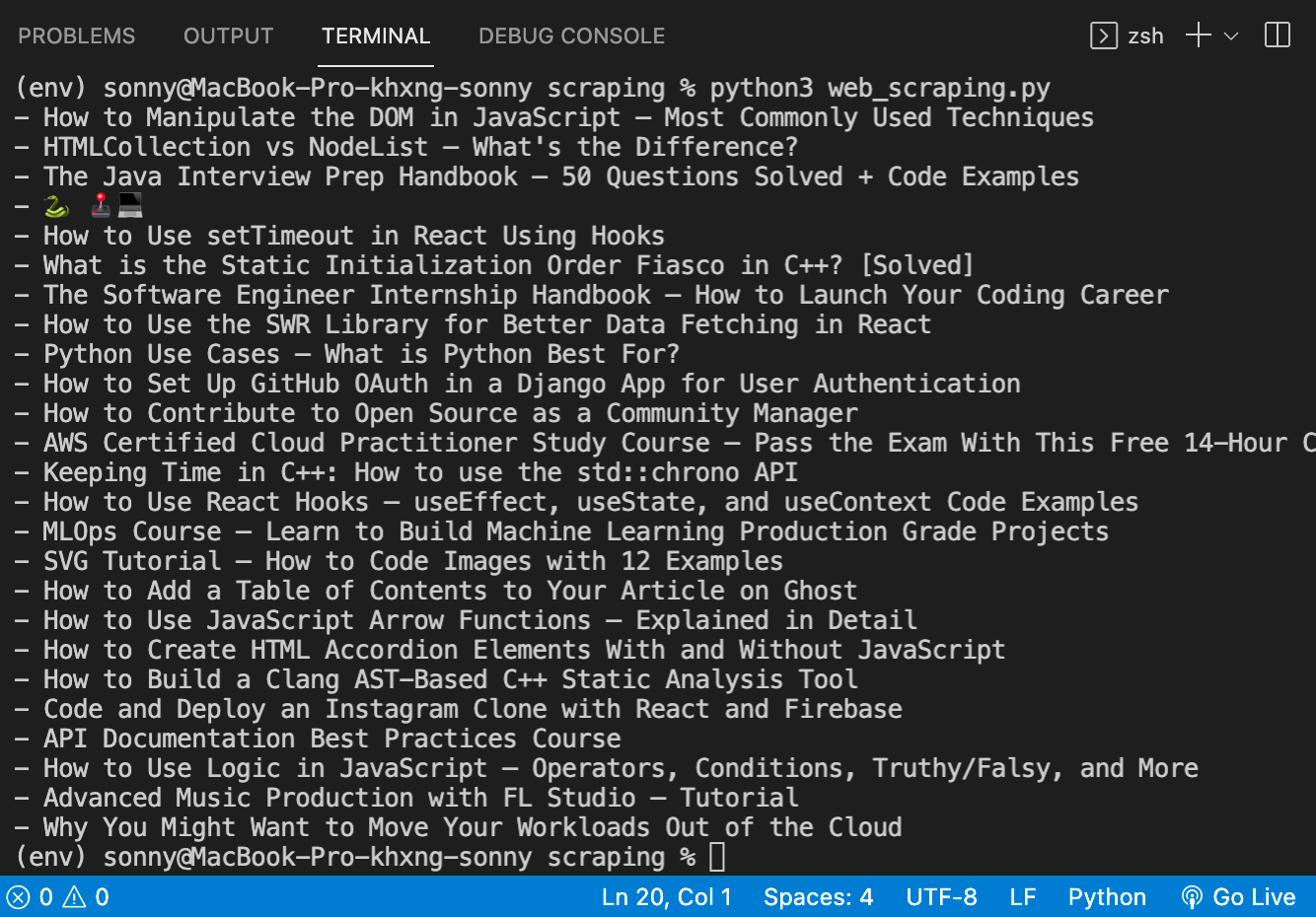 ชื่อบทความที่ได้ scrape มา
ชื่อบทความที่ได้ scrape มา
หน้าเว็บที่ต้อง Login หรือ Authen?
หลายคนน่าจะสงสัยว่า แล้วหน้าเว็บที่ต้องล็อกอินหรือมีระบบ authentication ผู้ใช้ก่อนล่ะ เราจะสามารถทำ web scraping ได้ไหม หรือถ้าทำได้จะมีวิธีการทำอย่างไร เดี๋ยวเผื่อผมจะมาเขียนส่วนนี้ให้เพิ่มเติมครับ กดติดตามหรือ bookmark หน้าเว็บไว้ก่อนได้ครับ
นี่เป็นเพียงแค่จุดเริ่มต้นเท่านั้นครับ ยังมีอีกหลายส่วนที่เราอาจจะต้องลองคิดตามครับ เช่น
- Scrape ข้อมูลมาแล้วจะเก็บไว้ในไหนในรูปแบบไฟล์ เช่น CSV, Excel หรือเก็บใน Database, ฯลฯ เป็นต้น
- ข้อมูลที่ได้มาจะเอาไปทำอะไรต่อ ไปทำ report ไปทำ Data Visualization, ไปประยุกต์ใช้กับงานด้าน Web Dev ฯลฯ
แต่ก็หวังเป็นอย่างยิ่งว่าบทความนี้คงทำให้เพื่อน ๆ มองภาพรวมของการทำ Web Scraping ได้เป็นอย่างดี และสามารถนำไปต่อยอดหรือประยุกต์ในระดับสูงได้ตาม requirements ของแต่ละคนได้นะครับ
แชร์บทความนี้
บทความที่คุณอาจสนใจ